Sunday
Apr122009
Nonsense Charts
Check out these beautiful faux visualizations, or "nonsense charts" by Chad Hagen. Great work!


(via changethethought.com)
tagged  art, chad hagen, faux visualizations
art, chad hagen, faux visualizations
Check out these beautiful faux visualizations, or "nonsense charts" by Chad Hagen. Great work!
(via changethethought.com)
There's a great cheat sheet for time-travelers floating around online.

If I was about to take a one-way trip back in time, the first thing I would do would be to print out Wikipedia, on acid-free paper, at Kinkos. What about you?
I recently tried to purchase a Google Adword Ad that containted the word "iPod." Upon submitting the ad, I was told that the ad was not approved because I included the trademark term, "iPod."
What idiocy. Does Apple not want us to sell iPods for them? Frustrated, I Googled around and found out that a lot of other Apple resellers have had this problem. Tidbits has a comprehensive list of terms effected, including Apple, iPod, Shuffle, Mac, Mac Mini, iMac, iBook, PowerBook, Power Mac, iTunes, and iTMS.
Tidbits also has a work around, involving restricting your ad geographically and requesting an exception, so if you run into this problem, check it out.
A picture of a cup of coffee I uploaded to Wikipedia many years ago has become a feature picture! Fantastic. Here it is, for your viewing pleasure:

DATA: Facebook has an interesting post on interconnectivity among their users. Check it out.
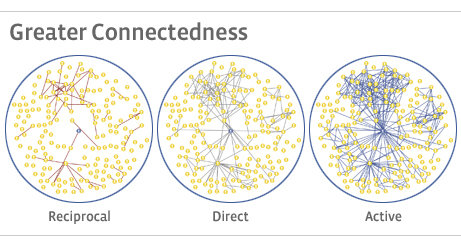
With greater connectedness has come the ability for people to influence one another with more speed and efficiency. We've seen this lead to people spreading information and organizing events on a mass scale, often within days and weeks. For example, within weeks of T-Mobile airing an advertisement, Facebook users organized thousands of people to recreate the ad with a "Silent Dance" at the same station.
I'm happy to announce that we're launching a public beta of Shopobot, a place to find deals online. This site gives consumers and businesses data about how much consumer goods have cost previously, and how much they cost now. It's a great resource, especially for bigger ticket items like cameras, mp3 players, and game systems. Anyway, check it out - and don't forget our Shopobot Blog! Feedback or bugs can be sent to us here on this blog or via the link in the footer of the website itself.
DATA: Sheesh, I'm starting to get dozens of spam messages a day now that have nothing but a link to a Google Group. Anyone else out there in the cloud dealing with this? Google, please crack down on the Google Spam Groups!
INFO SCIENCE: Technology Review reports:
An ambitious project to create an accurate computer model of the brain has reached an impressive milestone. Scientists in Switzerland working with IBM researchers have shown that their computer simulation of the neocortical column, arguably the most complex part of a mammal's brain, appears to behave like its biological counterpart. By demonstrating that their simulation is realistic, the researchers say, these results suggest that an entire mammal brain could be completely modeled within three years, and a human brain within the next decade.
The article's visualization is fascinating and gives me renewed respect for the people trying to reverse engineer the brain.

DATA:
Over on Ask Edward Tufte there's an interesting thread about "representing scale in concrete, understandable terms." It's a great read.
Something I was told twenty-five years ago (when RAM was a dollar a byte) was that the Bible was 5Mb as unformatted text. There are a million seconds in (roughly) eleven-and-a-half days, and a terabyte of seconds in something around 32,000 years.However, a good-quality large art book (ignoring file compression) could have half-a-gigabyte of illustrations, and a collection of maps as image files easily larger, so a terabyte would be somewhere around the fine art section of a big-city bookstore, or a reasonably sized personal library in a private house that included maps or illustrated books. "Library of Congress" may only be good guide if you leave out formatting and illustrations.
A terabyte is not big at all. If I could contain all the information I know about one other person in one byte, and their information about me similarly, then two people's knowledge of each other equals two bytes. Three people's knowledge is six bytes (factorial 3). By the time you reach fifteen people you are past a terabyte.
If, rather than a byte, you take a terabyte as the information you know of any person - one percent of a brainful say (estimates of the number of information connections in the brain vary from say a hundred terabytes to a terabyte squared) - and say six billion people on earth each knowing one hundred other people, then a terabyte is to the sum of human knowledge as a single atom is to the square of the number of atoms in the known universe - give or take a few.
UPDATE: After re-reading the last two paragraphs, I realized that the author made a mistake in his math. So, I submitted this post to the thread, but it may not appear since it is moderated.
Response to How big is a phone book, and other ways of illustrating size
Earlier in this thread, Martin Ternouth noted:"A terabyte is not big at all. If I could contain all the information I know about one other person in one byte, and their information about me similarly, then two people's knowledge of each other equals two bytes. Three people's knowledge is six bytes (factorial 3). By the time you reach fifteen people you are past a terabyte."
However, this isn't the case. If we visualized this example as a graph, each person would be a node, and known information about other people would be an edge between two nodes.
In the provided example, a complete graph (in other words, a connection between each node on the graph -- see http://en.wikipedia.org/wiki/Complete_graph) of 15 nodes, would not be 15! bytes (over a terabyte) as the author states, but would simply be 15(15-1), or 210 bytes. The author appears to have assumed this number would grow at a factorial rate since his example of three nodes satisfies this equation: 3! = 3(3-1), however at 15 this is not the case: 15! > 15(15-1).
DATA: Those ubergeeks at Google (can't we go a day without saying or typing Google anymore?) released an interesting paper on observed hard drive failures in their data centers. It's called, aptly enough, Failure Trends in a Large Disk Drive Population. While it doesn't name names and point out which brands are the best and worst -- it does provide a lot of interesting analysis on when the drive is most likely to fail along with the optimal operating performance. Give it a look.